
Paweł Woźny
2024-10-24
Treści
Upraszczanie świata: Symulacje intralogistyczne z wykorzystaniem FlexSim w firmie ASTOR
Upraszczanie świata: Symulacje intralogistyczne z wykorzystaniem FlexSim w firmie ASTOR
Symulacje procesów w przemyśle stają się nieodzownym narzędziem wspomagającym projektowanie, optymalizację oraz weryfikację systemów. W firmie ASTOR, w projektach intralogistycznych, korzystamy z narzędzia FlexSim, które wspiera nasze decyzje inżynieryjne oraz biznesowe. W artykule przedstawię nasze podejście do tworzenia symulacji, wskażę na znaczenie upraszczania modeli oraz poruszę wyzwania związane z odpowiednim doborem i przetwarzaniem danych wejściowych.
Rodzaje symulacji: skupienie na kluczowych elementach systemu
W naszym zespole koncentrujemy się na symulacjach systemów, w których jesteśmy dostawcą technologii. Przeważnie są to elementy rozwiązań EtE®flow oraz roboty mobilne Agilox. Oznacza to, że modele które tworzymy są z reguły proste, podnosząc szczegółowość tam, gdzie jest to niezbędne. Przygotowujemy symulacje z myślą o jak najszybszym wdrożeniu, aby już na wczesnym etapie projektu możliwe było zrozumienie i weryfikacja podstawowych założeń systemu.
Nasze symulacje pomagają w osiągnięciu kilku kluczowych celów:
- Weryfikacja hipotez – upewnienie się, że przyjęte założenia systemu są prawidłowe.
- Poznanie charakterystyki fragmentu systemu – zrozumienie, jak poszczególne elementy wpływają na całość.
- Identyfikacja miejsc do optymalizacji – poszukiwanie możliwości usprawnień.
- Identyfikacja potencjalnych zagrożeń – zminimalizowanie ryzyka wprowadzania nowych rozwiązań.
- Przekonanie inwestora – dostarczenie solidnych danych wspierających decyzje inwestycyjne.
Upraszczanie świata: skupienie na istotnych częściach systemu
Jednym z kluczowych aspektów naszej pracy jest upraszczanie modelowanych systemów. Skupiamy się na elementach, które są kluczowe dla symulacji, uogólniając resztę. Taki proces pozwala nam nie tylko zaoszczędzić czas, ale także zwiększa czytelność wyników symulacji. Na przykład, jeżeli nasz element systemu znajduje się w środku przepływu materiałów, upraszczamy elementy znajdujące się przed nim i za nim, a także komponenty stanowisk, z którymi współpracuje.
Dla niektórych obserwatorów takie podejście może wyglądać na zbyt radykalne lub trywializujące. Nic bardziej mylnego. Upraszczanie wymaga czasu, analizy, świadomych decyzji oraz głębokiego zrozumienia procesów i zależności pomiędzy elementami systemu.
Granice modelowania: określenie zakresu symulacji
Symulowane przez nas systemy zazwyczaj nie są systemami zamkniętymi – współpracują z resztą zakładu produkcyjnego, której nie zamierzamy modelować na takim samym poziomie szczegółowości. Musimy zatem świadomie określić granice pomiędzy tym, co jest modelowane szczegółowo, a tym, co upraszczamy. Również zachowanie obiektów poza tymi granicami powinno być zamodelowane w sposób odpowiedni, by nie wpłynęło negatywnie na wyniki symulacji.
Uproszczenie danych wejściowych: podejście z ostrożnością
Jednym z kluczowych wyzwań w projekcie symulacyjnym jest odpowiednie uproszczenie danych wejściowych. Dane produkcyjne, layout zakładu oraz opisy procesów są podstawowymi materiałami źródłowymi i jako takie powinny być traktowane do końca projektu symulacyjnego. Uproszczenie tych danych powinno być realizowane bardzo ostrożne i świadome. Problem polega na tym, że niewłaściwe uproszczenie może prowadzić do nieoczywistych błędów, które mogą nie być widoczne podczas działania symulacji.
Zanim przystąpimy do modelowania, powinniśmy zrobić dwie rzeczy:
- Określić granice dla podmiotu i reszty systemu – jasno zdefiniować, które elementy będą modelowane szczegółowo, a które w sposób uproszczony.
- Zaproponować charakterystykę obiektów znajdujących się poza granicą naszego zainteresowania – w formie interfejsów, aby zapewnić realistyczne i odpowiednie wyniki symulacji.
Przykład symulacji: transport autonomiczny za pomocą robotów mobilnych
Przyjrzyjmy się prostemu przykładowi transportu autonomicznego z wykorzystaniem robotów mobilnych Agilox ONE. W zadaniu tym istnieją dwa rodzaje misji: pierwsza polega na odbieraniu palet z magazynu i dostarczaniu ich do linii produkcyjnych, a druga na odbieraniu gotowych palet z linii i transportowaniu ich z powrotem do magazynu.
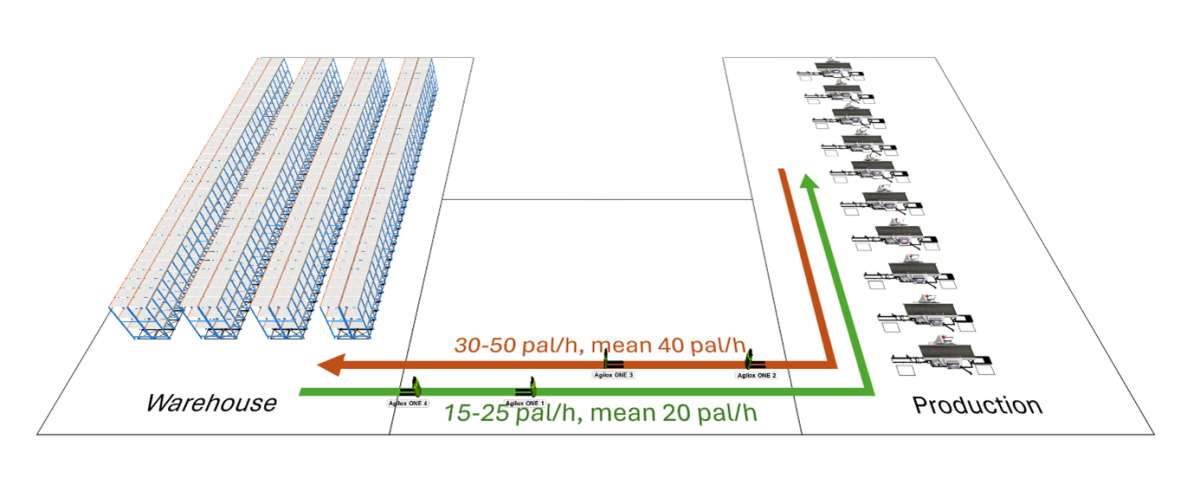
Dla nas jako dostawcy robotów mobilnych, najbardziej interesująca jest część transportowa. W związku z tym, że nie chcemy modelować szczegółów procesów w magazynie i na produkcji, stosujemy odpowiednie uproszczenia. Kluczowe jest jednak, jak je zamodelujemy, aby nie wpłynęły negatywnie na jakość symulacji.
Dane wejściowe:
Oprócz szczegółowego opisu procesu i layoutu zakładu, dostajemy dane wydajnościowe. W zależności od dostępnych informacji, możemy mieć do czynienia z różnymi scenariuszami:
- Precyzyjne historie zleceń produkcyjnych z sygnaturą czasu – najbardziej szczegółowe dane,
- Wartości minimalne i maksymalne wydajności godzinowych lub zmianowych – bardziej ogólne dane,
- Wartości średnie godzinowe lub zmianowe – najmniej szczegółowe dane.
W przypadku, gdy dysponujemy precyzyjnymi danymi historycznymi, możemy z dużą pewnością postawić twarde granice między strefą magazynu, transportu a produkcji, traktując obszary magazynu i produkcji jako tzw. „czarne skrzynki” (black boxes), a ich zachowanie w modelu oprzeć na danych historycznych. Takie podejście jest z reguły słuszne i zapewnia realistyczne wyniki.
Jednak nie zawsze mamy dostęp do tak szczegółowych danych. Gdy dysponujemy tylko średnimi wydajnościami lub wartościami skrajnymi, musimy być bardziej ostrożni w modelowaniu tych „czarnych skrzynek”. Czy te obszary produkcji zamodelować i proaktywnie przedstawić w formie ogólnych rozkładów statystycznych? Oczywiście że możemy, ale czy to będzie słuszne? Może okazać się, że nie. Co więcej, bardzo długo możemy nie zdawać sobie z tego sprawy.
Załóżmy, że do tego projektu otrzymaliśmy dane wydajnościowe w formie średnich oraz minimalnych i maksymalnych godzinowych wartości.
Magazyn: średnio 20, min 15, max 25 palet na godzinę
Produkcja: średnio 40, min 30, max 50 palet na godzinę
Wybór metody modelowania: przykłady i konsekwencje
Rozważmy dwa podejścia do takich danych:
Podejście pierwsze:
Założenie, że magazyn wydaje 15-25 palet na godzinę, a produkcja 30-50 palet na godzinę, przyjmując równomierne rozkłady zleceń. Możemy założyć, że zlecenia będą się pojawiać w interwałach czasowych pomiędzy 144 a 240 sekund (dla magazynu) oraz 72 a 120 sekund (dla produkcji). Oba obszary możemy zamodelować w formie źródeł dla zleceń bazujących na rozkładzie statystycznym. Jedno źródło dla magazynu i jedno dla produkcji. Stawiamy w ten sposób twardą granice pomiędzy systemem autonomicznych robotów a resztą zakładu. Uogólniając i nie wnikając w procesy które tam rzeczywiści zachodzą.
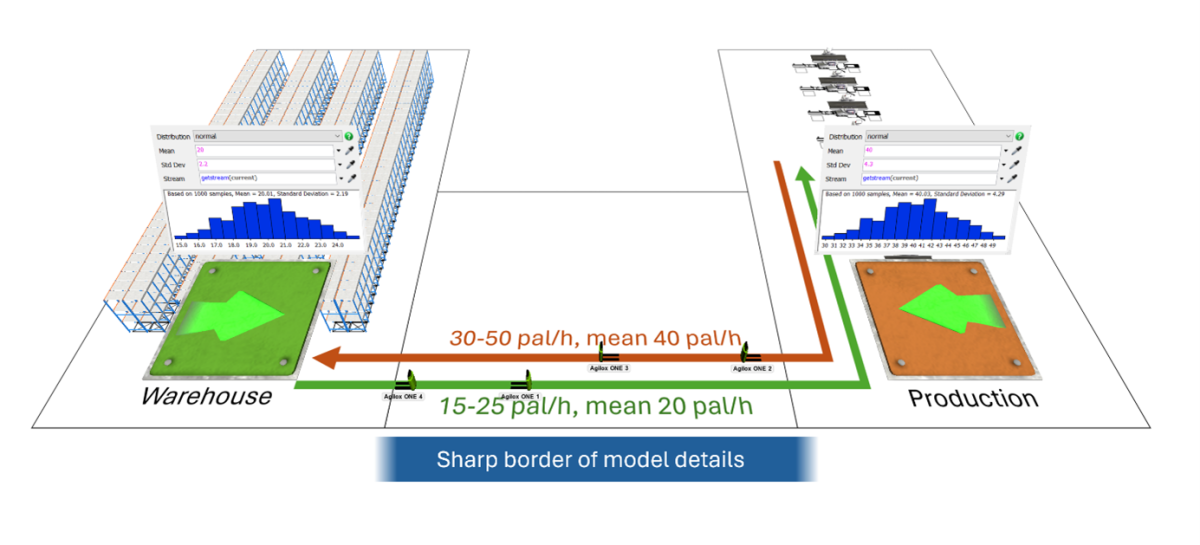
Na pierwszy rzut oka wszystko wydaje się w porządku. Wartości interwałów w obu przedziałach wydają się bezpieczne z punktu widzenia czasów operacyjnych robotów Agilox ONE, ich dokowania i zwalniania miejsc odkładczych. Co więc może pójść nie tak? Gdzie jest haczyk?
Może okazać się, że w tym podejściu przyjęliśmy zbyt duże uproszczenie o czym jeszcze nie wiemy. Co gorsze: mogliśmy nieświadomie poczynić pewne założenia w danych, które mogą okazać się ich nadinterpretacją.
Podejście drugie:
Brak precyzyjnych danych historycznych powinien pobudzić nas do ciekawości i przeprowadzenia śledztwa, staramy się zrozumieć, jak powstały wartości średnie i skrajne. Może okazać się, że zmienność produkcji jest znacznie bardziej skomplikowana, a magazyn działa w sposób bardziej złożony niż zakładano. Wówczas modelowanie musi uwzględniać te złożoności, aby uzyskać realistyczne i wiarygodne wyniki. Być może okaże się wtedy, że podane liczby jako takie są prawdziwe, ale po stronie magazynu pracują dwa wózki widłowe, natomiast po stronie produkcji znajduje się np. dziesięć maszyn. Co z tego wynika? Nie zmieniliśmy nic w danych a jednak ostateczne zachowanie obu tych stref jako źródło zleceń może wyglądać zupełnie inaczej niż przyjęliśmy poprzednio.
15-25 palet na godzinę, wydawanych przez dwóch wózkowych nie powinno być reprezentowane przez poprzedni rozkład statystyczny tych liczb. Być może, możemy dopasować inny rozkład. Wiemy, że wózkowi mogą pracować równolegle, a więc minimalny interwał pojawiania się zleceń na wydaniu z magazynu teoretycznie może wynosić 0 sekund! – dwie palety wydawane naraz.
Jeżeli przewidzieliśmy w layoucie kilka miejsc buforowych to zjawisko nie musi być problemem. Natomiast jest ono znacznie bardziej wyraźne w strefie produkcyjnej. 30-50 palet na godzinę generowanych przez dziesięć linii produkcyjnych. Tam nic nie stoi na przeszkodzie, aby wszystkie linie wydały zlecenie w tym samym momencie. Jest to mało prawdopodobnie, a jednak możliwe. W takiej sytuacji dziesięć zleceń pojawia się naraz, a nie jak błędnie założyliśmy w interwałach między 72 a 120 sekund.
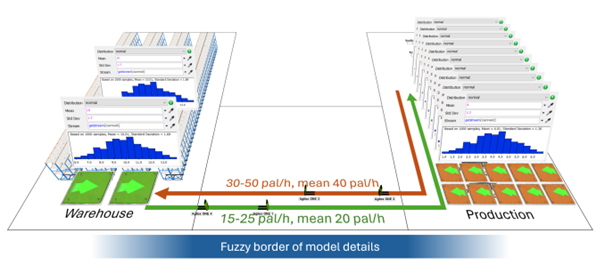
Jak sobie z tym poradzić? Można opuścić rękawice i modelować część magazynu i produkcyjną w wysokiej szczegółowości. Ale tego nie chcemy robić. Możemy zamodelować ją nadal w sposób uproszczony np. strefę magazynu jako dwa źródła (dwa wózki widłowe) o indywidualnych rozkładach na podstawie badań lub wywiadu, być może nawet charakterystycznych dla konkretnego operatora lub typu wózka. Natomiast po stronie produkcji również zamodelować dziesięć niezależnych źródeł z ich indywidualnymi charakterystykami, nadal nie wchodząc w szczegóły procesów tych maszyn. Dzięki temu w późniejszym etapie będziemy mogli analizować np. jak zależności w przesunięciu w fazie pomiędzy zleceniami wpływają na sprawność systemu.
Wnioski i zalecenia
Konkludując. Posiadając precyzyjne dane, nie próbujmy ich nadmiernie upraszczać, jeśli można tego uniknąć. Niosą ze sobą wartościowe informacje, które mogą być potrzebne nawet w uproszczonym modelu symulacyjnym. Z drugiej strony: otrzymując uproszczone dane, bądźmy dociekliwi, spróbujmy zrozumieć z czego się one biorą. Zajrzyjmy trochę dalej poza implementowany przez nas element systemu, zamiast stawiać twarde granice.
Ostatnie zdanie prowadzi do pewnego wniosku: stawianie twardych granic w szczegółowości modelowania może czasem prowadzić do błędnych wyników, dlatego warto rozważyć podejście bardziej elastyczne, z granicami „rozmytymi”, które pozwalają na bardziej realistyczne odwzorowanie rzeczywistości. Posiadanie pełnych i precyzyjnych danych to luksus, ale nawet gdy ich brakuje, odpowiednie zrozumienie i przetworzenie dostępnych informacji może przynieść wartościowe rezultaty.
Wracając do naszego przykładu. Jakich problemów możemy się spodziewać po ujawnieniu niedopatrzenia? Można spodziewać się pytań typu: Czy mamy zapewnione tyle miejsc buforowych? Czy jest tam możliwość dokowania się kilku robotów naraz? Czy musimy odbierać i dostarczać just-in-time? Czy palety, magazyn lub maszyny mogą poczekać? Ale to już jest temat na inne opracowanie.


